
流行的機(jī)器學(xué)習(xí)算法,如 XGBoost 和 LightGBM,充分利用了這一概念。理解 boosting 有助于闡明為什么它是一個(gè)如此強(qiáng)大的工具并適用于當(dāng)今的許多分類問題。
提升樹是什么?
Boosting 是將多個(gè)弱分類器組合成一個(gè)強(qiáng)分類器的概念。弱分類器是預(yù)測能力較差的模型,其性能僅略好于隨機(jī)猜測。Adaboost 就是這種算法的一個(gè)例子,它通過組合樹樁來創(chuàng)建一個(gè)強(qiáng)分類器。樹樁是深度為 1 的決策樹。我們可以通過一個(gè)簡單的圖解來更好地理解它
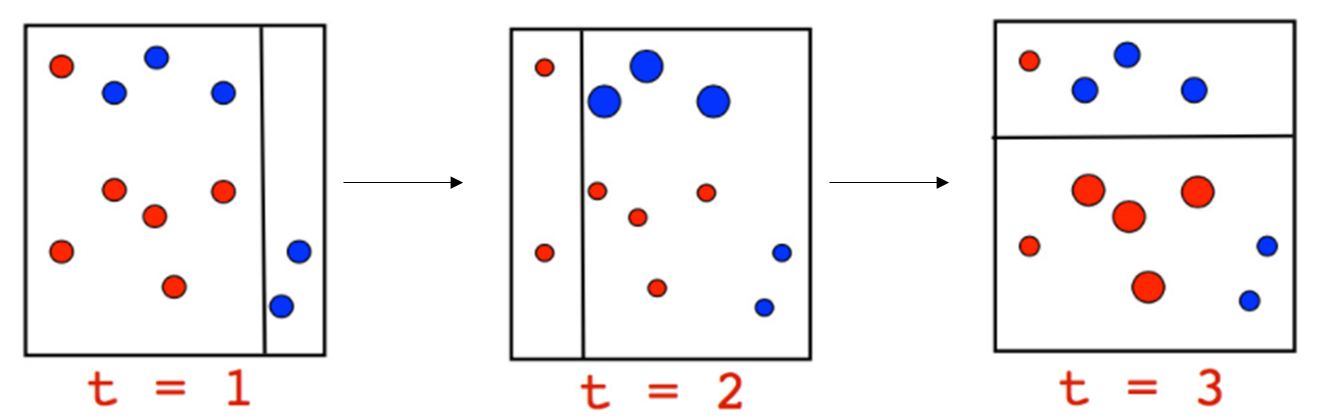
每個(gè)圓圈的大小顯示了 Adaboost 分配給該點(diǎn)的權(quán)重(錯(cuò)誤分類的點(diǎn)更高)。我們可以清楚地看到,在前一個(gè)時(shí)間步之后,錯(cuò)誤分類點(diǎn)的權(quán)重更大。決策樹樁是弱學(xué)習(xí)器,它們無法自行對(duì)點(diǎn)進(jìn)行高精度分類。
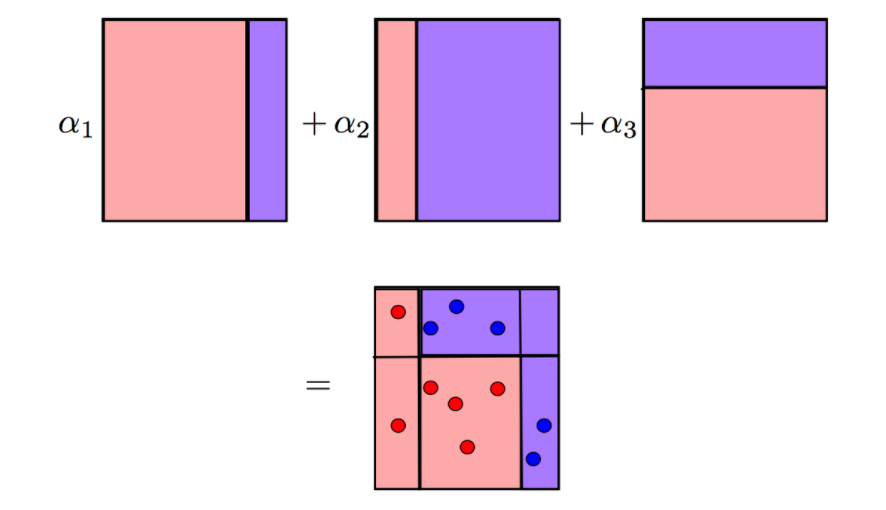
Adaboost 通過對(duì)這些弱學(xué)習(xí)器進(jìn)行加權(quán)來組合它們,最終給出一個(gè)強(qiáng)學(xué)習(xí)器。
算法背后的數(shù)學(xué):

以上算法步驟說明如下:
1.我們首先計(jì)算數(shù)據(jù)集中每個(gè)觀測值的樣本權(quán)重(初始化為 1/m)。
2.使用最佳分割構(gòu)造一個(gè)樹樁,最小化誤差(例如,最小化殘差平方和)
3.計(jì)算分類/回歸誤差(例如,均方誤差或分類誤差)
4.計(jì)算一個(gè)樹樁的數(shù)量:
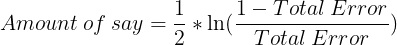
5. 計(jì)算新的樣本權(quán)重。這將強(qiáng)調(diào)下一個(gè)樹樁正確分類當(dāng)前樹樁的錯(cuò)誤分類觀察
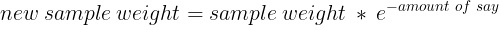
對(duì)于正確分類的觀察
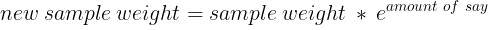
對(duì)于錯(cuò)誤分類的觀察
6. 將新的樣本權(quán)重歸一化,加起來為 1
7. 重復(fù)步驟 2-7 直到收斂(達(dá)到最大樹樁數(shù)或錯(cuò)誤超過最小閾值)
Adaboost 的局限性:
當(dāng)數(shù)據(jù)中存在強(qiáng)異常值時(shí),Adaboost 容易過度擬合。這激發(fā)了梯度提升算法的推廣,也稱為梯度提升機(jī) (GBM)。
小結(jié)
提升(Boosting)方法是一種常用的統(tǒng)計(jì)學(xué)習(xí)方法,應(yīng)用廣泛且有效。在分類問題中,它通過改變訓(xùn)練樣本的權(quán)重,學(xué)習(xí)多個(gè)分類器,并將這些分類器進(jìn)行線性組合,提高分類的性能。